Publications
2024
-
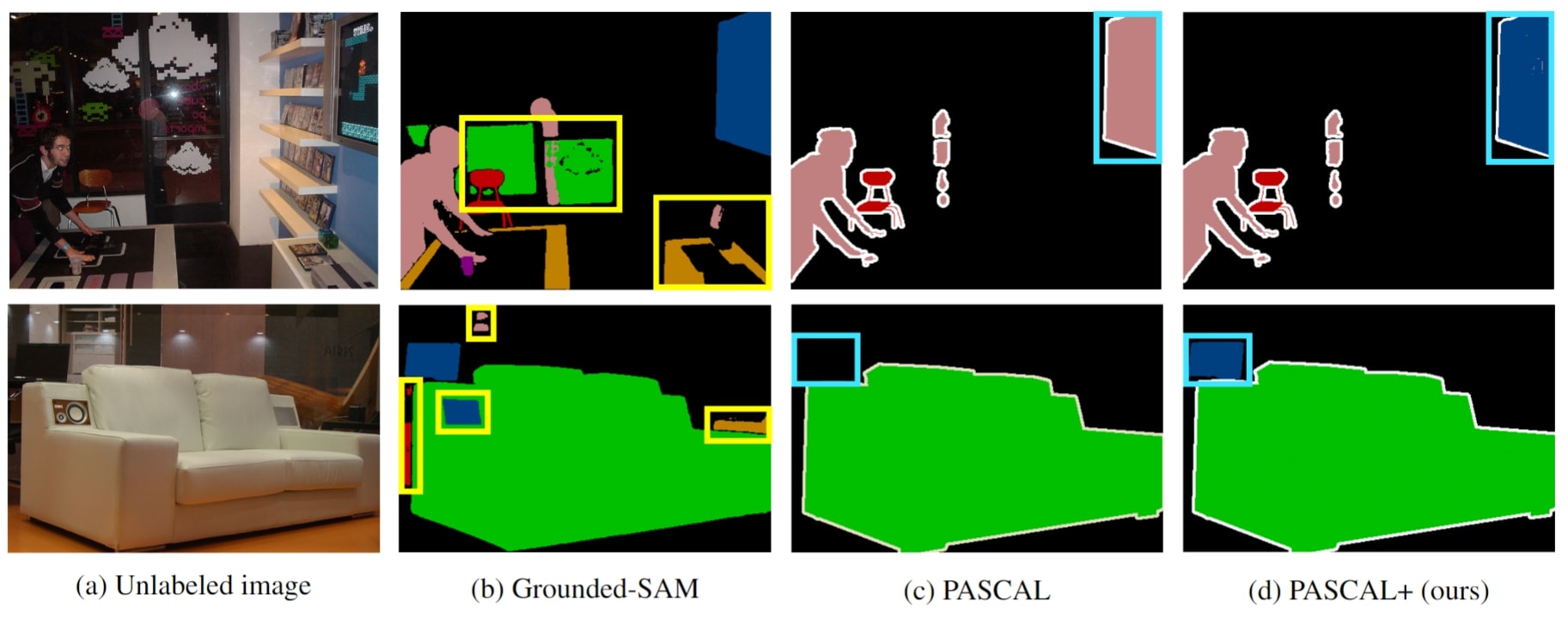 Active Label Correction for Semantic Segmentation with Foundation ModelsHoyoung Kim, Sehyun Hwang, Suha Kwak, and Jungseul Ok (*equal contribution)International Conference on Machine Learning (ICML), 2024
Active Label Correction for Semantic Segmentation with Foundation ModelsHoyoung Kim, Sehyun Hwang, Suha Kwak, and Jungseul Ok (*equal contribution)International Conference on Machine Learning (ICML), 2024Training and validating models for semantic segmentation require datasets with pixel-wise annotations, which are notoriously labor-intensive. Although useful priors such as foundation models or crowdsourced datasets are available, they are error-prone. We hence propose an effective framework of active label correction (ALC) based on a design of correction query to rectify pseudo labels of pixels, which in turn is more annotator-friendly than the standard one inquiring to classify a pixel directly according to our theoretical analysis and user study. Specifically, leveraging foundation models providing useful zero-shot predictions on pseudo labels and superpixels, our method comprises two key techniques: (i) an annotator-friendly design of correction query with the pseudo labels, and (ii) an acquisition function looking ahead label expansions based on the superpixels. Experimental results on PASCAL, Cityscapes, and Kvasir-SEG datasets demonstrate the effectiveness of our ALC framework, outperforming prior methods for active semantic segmentation and label correction. Notably, utilizing our method, we obtained a revised dataset of PASCAL by rectifying errors in 2.6 million pixels in PASCAL dataset.
-
 Extreme Point Supervised Instance SegmentationHyeonjun Lee, Sehyun Hwang, and Suha KwakIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Extreme Point Supervised Instance SegmentationHyeonjun Lee, Sehyun Hwang, and Suha KwakIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024This paper introduces a new weakly supervised learning approach for instance segmentation using extreme points, i.e., the topmost, leftmost, bottommost, and rightmost points of an object. Although these points are readily available in the modern bounding box annotation process and offer strong clues for precise segmentation, they have received less attention in the literature. Motivated by this, our study explores extreme point supervised instance segmentation to further enhance performance at the same annotation cost with box-supervised methods. Our work considers extreme points as a part of the true instance mask and propagates them to identify potential foreground and background points, which are all together used for training a pseudo label generator. Then pseudo labels given by the generator are in turn used for supervised learning of our final model. Our model generates high-quality masks, particularly when the target object is separated into multiple parts, where previous box-supervised methods often fail. On three public benchmarks, our method significantly outperforms existing box-supervised methods, further narrowing the gap with its fully supervised counterpart.


2023
-
 Active Learning for Semantic Segmentation with Multi-class Label QuerySehyun Hwang, Sohyun Lee, Hoyoung Kim, Minhyeon Oh, Jungseul Ok, and Suha KwakConference on Neural Information Processing Systems (NeurIPS), 2023
Active Learning for Semantic Segmentation with Multi-class Label QuerySehyun Hwang, Sohyun Lee, Hoyoung Kim, Minhyeon Oh, Jungseul Ok, and Suha KwakConference on Neural Information Processing Systems (NeurIPS), 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
-
 Adaptive Superpixel for Active Learning in Semantic SegmentationHoyoung Kim, Minhyeon Oh, Sehyun Hwang, Suha Kwak, and Jungseul OkInternational Conference on Computer Vision (ICCV), 2023
Adaptive Superpixel for Active Learning in Semantic SegmentationHoyoung Kim, Minhyeon Oh, Sehyun Hwang, Suha Kwak, and Jungseul OkInternational Conference on Computer Vision (ICCV), 2023Learning semantic segmentation requires pixel-wise annotations, which can be time-consuming and expensive. To reduce the annotation cost, we propose a superpixel-based active learning (AL) framework, which collects a dominant label per superpixel instead. To be specific, it consists of adaptive superpixel and sieving mechanisms, fully dedicated to AL. At each round of AL, we adaptively merge neighboring pixels of similar learned features into superpixels. We then query a selected subset of these superpixels using an acquisition function assuming no uniform superpixel size. This approach is more efficient than existing methods, which rely only on innate features such as RGB color and assume uniform superpixel sizes. Obtaining a dominant label per superpixel drastically reduces annotators’ burden as it requires fewer clicks. However, it inevitably introduces noisy annotations due to mismatches between superpixel and ground truth segmentation. To address this issue, we further devise a sieving mechanism that identifies and excludes potentially noisy annotations from learning. Our experiments on both Cityscapes and PASCAL VOC datasets demonstrate the efficacy of adaptive superpixel and sieving mechanisms.


2022
-
 Combating label distribution shift for active domain adaptationSehyun Hwang, Sohyun Lee, Sungyeon Kim, Jungseul Ok, and Suha KwakEuropean Conference on Computer Vision (ECCV), 2022Qualcomm Innovation Fellowship Winner, Gold Prize at IPIU paper Award
Combating label distribution shift for active domain adaptationSehyun Hwang, Sohyun Lee, Sungyeon Kim, Jungseul Ok, and Suha KwakEuropean Conference on Computer Vision (ECCV), 2022Qualcomm Innovation Fellowship Winner, Gold Prize at IPIU paper AwardWe consider the problem of active domain adaptation (ADA) to unlabeled target data, of which subset is actively selected and labeled given a budget constraint. Inspired by recent analysis on a critical issue from label distribution mismatch between source and target in domain adaptation, we devise a method that addresses the issue for the first time in ADA. At its heart lies a novel sampling strategy, which seeks target data that best approximate the entire target distribution as well as being representative, diverse, and uncertain. The sampled target data are then used not only for supervised learning but also for matching label distributions of source and target domains, leading to remarkable performance improvement. On four public benchmarks, our method substantially outperforms existing methods in every adaptation scenario.
-
 Learning debiased classifier with biased committeeNayeong Kim, Sehyun Hwang, Sungsoo Ahn, Jaesik Park, and Suha KwakConference on Neural Information Processing Systems (NeurIPS), 2022
Learning debiased classifier with biased committeeNayeong Kim, Sehyun Hwang, Sungsoo Ahn, Jaesik Park, and Suha KwakConference on Neural Information Processing Systems (NeurIPS), 2022Neural networks are prone to be biased towards spurious correlations between classes and latent attributes exhibited in a major portion of training data, which ruins their generalization capability. We propose a new method for training debiased classifiers with no spurious attribute label. The key idea is to employ a committee of classifiers as an auxiliary module that identifies bias-conflicting data, i.e., data without spurious correlation, and assigns large weights to them when training the main classifier. The committee is learned as a bootstrapped ensemble so that a majority of its classifiers are biased as well as being diverse, and intentionally fail to predict classes of bias-conflicting data accordingly. The consensus within the committee on prediction difficulty thus provides a reliable cue for identifying and weighting bias-conflicting data. Moreover, the committee is also trained with knowledge transferred from the main classifier so that it gradually becomes debiased along with the main classifier and emphasizes more difficult data as training progresses. On five real-world datasets, our method outperforms prior arts using no spurious attribute label like ours and even surpasses those relying on bias labels occasionally.
-
 Learning to Detect Semantic Boundaries with Image-Level Class LabelsNamyup Kim*, Sehyun Hwang*, and Suha Kwak (*equal contribution)International Journal of Computer Vision (IJCV), 2022Honorable Mention @ Samsung HumanTech Paper Award
Learning to Detect Semantic Boundaries with Image-Level Class LabelsNamyup Kim*, Sehyun Hwang*, and Suha Kwak (*equal contribution)International Journal of Computer Vision (IJCV), 2022Honorable Mention @ Samsung HumanTech Paper AwardThis paper presents the first attempt to learn semantic boundary detection using image-level class labels as supervision. Our method starts by estimating coarse areas of object classes through attentions drawn by an image classification network. Since boundaries will locate somewhere between such areas of different classes, our task is formulated as a multiple instance learning (MIL) problem, where pixels on a line segment connecting areas of two different classes are regarded as a bag of boundary candidates. Moreover, we design a new neural network architecture that can learn to estimate semantic boundaries reliably even with uncertain supervision given by the MIL strategy. Our network is used to generate pseudo semantic boundary labels of training images, which are in turn used to train fully supervised models. The final model trained with our pseudo labels achieves an outstanding performance on the SBD dataset, where it is as competitive as some of previous arts trained with stronger supervision.


